| Version: 2.9.4 |
クラス: wxString, wxArrayString, wxStringTokenizer
wxString は任意の長さで、任意の Unicode 文字を含む Unicode 文字列を表すクラスです。
このクラスは文字列クラスに含まれていると考えるであろうすべての標準的な文字列操作機能を持っています: 動的なメモリ管理 (新しい文字にあわせて文字列を拡張します)、他の文字列や C 文字列からの構築、代入演算子、各文字へのアクセス、文字列の結合と比較、部分文字列の抽出、大文字小文字の変換、トリムと (スペースによる) パディング、検索と置換、C 言語風の printf (wxString::Printf ) やストリーム風の挿入関数などです。すべての関数の一覧は wxString を参照してください。
wxString クラスは wxWidgets 3.0 では完全に書き直されますが、ANSI リテラル文字列を使用する既存のコードを以前のバージョンと同じように動作させるために様々なことを行っています。
wxWidgets 3.0 から wxString の内部エンコーディングとして Windows では (Unicode コード単位を wchar_t に格納する) UTF-16 を、Unix、Linux、Mac OS X では (Unicode コード単位を char に格納する) UTF-8 を使用します。
コード単位 と コードポイント の定義については Unicode 表現と用語 の段落を参照してください。
実装を単純にするため、wxUSE_UNICODE_WCHAR==1 のとき (例えば Windows) の wxString では コードポイントごとのインデックス の代わりに コード単位ごとのインデックス を使用し、サロゲートペアについては考慮しません; つまり、コードポイントは常に 1 コード単位に格納されているものと仮定するということですが、これは BMP (基本多言語面) の文字にしか当てはまりません。したがって、Windows で wxString に格納された UTF-16 文字列を走査するときには、自分で サロゲートペア を考慮する必要があります。(ただ、画面への文字列の描画など、Windows は元々 UTF-16 のサロゲートペアに対応しています)
wxUSE_UNICODE_WCHAR==1 のときの wxString の振る舞いは UCS-2 エンコーディングに似ていますが、wxString を完全に UCS-2 エンコーディングとみなすことはできません。なぜなら、BMP 以外のコードポイントをふたつのコードポイントとして (つまり、サロゲートペアとして; ただし、すでに述べたように wxString はそれらを異なるふたつのコードポイントとして扱います) wxString に格納することができるためです。代わりに wxUSE_UNICODE_UTF8==1 (例えば、Linux、Mac OS X) とした場合、wxString は BMP 以外の文字でも (コードポイントごとのインデックス として実装されているため) UTF8 マルチバイトシーケンスとして扱います。そのため、完全に透過的な方法で UTF8 を使用することができます。
例:
// 最初のテストでは Unicode BMP 外の文字を使用する: wxString test = wxString::FromUTF8("\xF0\x90\x8C\x80"); // U+10300 は "OLD ITALIC LETTER A" で、Unicode Plane 1 の一部である // UTF8 では 0xF0 0x90 0x8C 0x80 として符号化される // これは単一の Unicode コードポイントとして次のように符号化される: // - Windows では UTF16 サロゲートペア // - Linux では UTF8 マルチバイトシーケンス // (ただし終端の NULL は除く) wxPrintf("wxString reports a length of %d character(s)", test.length()); // Linux では "wxString reports a length of 1 character(s)" と表示される // Windows では "wxString reports a length of 2 character(s)" と表示される // これは Windows の wxString はサロゲートペアに対応していないからだ! // ふたつ目のテストでは Unicode BMP の文字を使用する: wxString test2 = wxString::FromUTF8("\x41\xC3\xA0\xE2\x82\xAC"); // これは大文字の A、'グレーブ付きの小文字の a'、 // 'ユーロ記号' を UTF8 で符号化したもので、 // 3 個の Unicode コードポイントは次のように符号化される: // - Windows では 3 個の UTF16 コード単位 // - Linux では 6 個の UTF8 コード単位 // (ただし終端の NULL は除く) wxPrintf("wxString reports a length of %d character(s)", test2.length()); // Linux では "wxString reports a length of 3 character(s)" と表示される // Windows では "wxString reports a length of 3 character(s)" と表示される
上で述べたことをきちんと説明するために、上記の例のふたつ目の文字列に注目してください; この文字列は 3 個の文字と終端の NULL で構成されています:
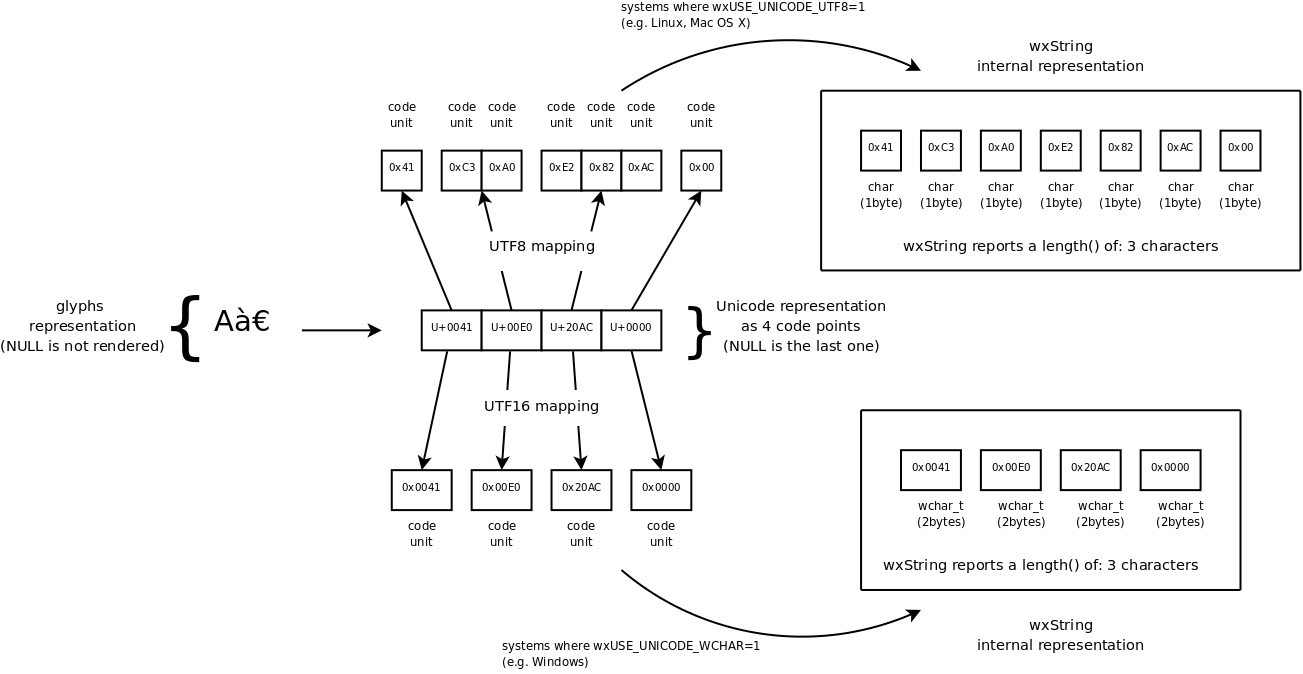
見て分かるように、UTF16 は (BMP の文字については) そのまま符号化しており、この例の UTF16 wxString では 8 バイトを消費します。UTF8 の符号化はより複雑で、この例では 7 バイトを消費します。
一般に、主にラテン文字を含む文字列について、UTF8 は必要なメモリ消費量において UTF16 よりも大きな利点がありますが、文字列長の計算などの共通操作を行なうために、より多くの計算を必要とします。
最後に、Unicode コード単位を格納するために wxString で使用される型 (wchar_t または char) は常に wxStringCharType として typedef されます。
wxString::To8BitData 関数と wxString::From8BitData 関数を使用して、wxString にバイナリデータ (NUL を含むこともできます) を格納することができます。
NUL 文字も格納できるとは言え、現在の実装ではいくつかの関数が NUL 文字を含む場合にうまく動作しないことに注意してください。
ただし、wxMemoryBuffer のように、このことを行なうためのより適切なクラスが他に存在します。バイナリデータを扱うために wxStreamBuffer、wxMemoryOutputStream、wxMemoryInputStream についても参照したいと思うことでしょう。
C 文字列を直接使用する代わりに特別な文字列クラスを使用する利点は、多くの文字列クラスが存在することから明らかと言えます。もっとも重要な利点は、C 文字列の場合、メモリの割り当てと解放を忘れずに行なう必要がある点です; また、固定サイズのバッファを使用すると大抵バッファオーバーランを引き起こします。最後に、C++ では標準の文字列クラス (std::string) が用意されています。それなのになぜ wxString が必要なのでしょうか?これにはいくつかの利点があります:
std::string (Linux、Unix、OS X の UTF8 モード時) または std::wstring (Windows の UTF16 モード時) を内部的に使用します。したがって、wxString はその性能上の特徴を std::string から引き継ぐことになります。 std::string クラスの機能の 90% と互換性があります。 std::wstring へマッピングされます。 std::string を含む) 他の文字列クラスを wxString へ変換することによる性能劣化が発生しません。しかし、同様にいくつかの問題も存在します。もっとも重要な問題はおそらく、まったく同じことを行なう関数が複数存在することです: 例えば、文字列の長さを取得するために wxString::length()、wxString::Len()、wxString::Length() のどれでも使用できます。他の小文字の関数のほとんどがそうであるように、最初の関数は std::string と互換性があります。二番目の関数は wxString "ネイティブ" の関数で、最後の関数は wxWidgets 1.xx の形式です。
そのため、どれを使うのが良いのでしょう? std::string 互換の関数を使用することを強く推奨します! そうすることで、(std::string に関する知識はあっても wxString のことは知らないであろう) 他の C++ プログラマにとってより馴染みのあるコードにできますし、(wxWidgets 外でコードを使用するときは wxString を std::string として typedef することで) wxWidgets とそれ以外のプログラムで同じコードを再利用することもできます。また、wxWidgets の将来のバージョンとの互換性も保てます。なぜなら、遅かれ早かれ、おそらく wxWidgets で std::string を使用し始めるためです。
std::string に対応する関数が存在しない場合は新しい wxString 関数を使用するようにし、wxWidgets 1.xx 版を使用しないようにしてください。これらの関数は非推奨であり、将来のバージョンでは削除されるかもしれません。
おそらく、このクラスを使用する際の一番の罠は const char * への暗黙の型変換演算子です。変換を行なうタイミングを明確にするために、代わりに wxString::c_str() を使用するようにしてください。暗黙の型変換の具体的な危険性は以下のコードで分かると思います:
// この関数は入力された文字列を大文字に変換し、画面に表示した上で // 結果を返却する const char *SayHELLO(const wxString& input) { wxString output = input.Upper(); printf("Hello, %s!\n", output); return output; }
この 3 行の中にふたつの分かりにくいバグが含まれています。最初のバグは printf() 関数の呼び出し部分に存在します。次のような場合であれば、コンパイラによって自動的に C 文字列への暗黙的な変換が行われます。
puts(output);
なぜなら、puts() の引数が const char * 型であることが分かっているためです。これは (引数が不明な型になる) 可変数引数を受け取る printf() では 行われません 。そのため、この関数呼び出しの結果は (文字列が正しく表示されることも含めて) 不定になりますが、一番起こりうるのはプログラムのクラッシュでしょう。この解決方法は wxString::c_str() を使用することです。この行を単純に次のように置き換えてください:
printf("Hello, %s!\n", output.c_str());
ふたつ目のバグは output を正しく返却できないことです。暗黙的な変換が再度行われるため、コードはコンパイルできますが、返却されるポインタはローカル変数のバッファを指すことになります。そして、このローカル変数は関数を抜けるとすぐに破棄されるため、その内容は完全に不定になります。この問題の解決方法も簡単で、C 文字列の代わりに wxString を返却するようにするだけです。
このことから、次のような一般的なアドバイスが可能です: 文字列を引数として受け取るすべての関数は const wxString& を受け取るべきで (こうすることで内部文字列への代入が早くなります)、文字列を返却するすべての関数は wxString を返却するべきです (これにより、安全にローカル変数を返却することができます)。
最後に、C リテラル文字列を Unicode へ変換するために wxString では現在のロケールを使用します。同じことが std::string との変換と、c_str() の戻り値に対しても行われます。この変換では wxConvLibc クラスのインスタンスが使用されます。wxCSConv と wxMBConv を参照してください。
前に述べたように、wxUSE_UNICODE_UTF8==1 の場合に wxString は可変長の UTF-8 エンコーディングを内部的に使用します。インデックスによる UTF-8 文字列へのアクセスは非常に 非効率的 です。なぜなら、1 文字が可変バイトで表されるため、該当する文字を見つけるために文字列全体を解析する必要があるためです。インデックスによる文字列の走査はよく使われるプログラミングテクニックであり、wxString では operator[]() を使用することを推奨していたため、wxString は最後に使用したインデックスをキャッシュするように実装されています。これにより、UTF-8 モードであっても文字列全体の走査を線形時間で行なうことができます。
とはいえ、(インデックスによるアクセスの代わりに) このように イテレータ を使用することを推奨します:
wxString s = "hello"; wxString::const_iterator i; for (i = s.begin(); i != s.end(); ++i) { wxUniChar uni_ch = *i; // なんらかの処理 }
多くのプログラムで文字列が使用されていますが、標準 C ライブラリではそれらのプログラムで使用できる関数をほんの少ししか提供していません。残念なことに、いくつかの関数は直感的でない振る舞いをします (例えば strncpy() は結果の文字列を常に NULL で終端させるとは限りません) し、一般的にあまり安全ではありません。(それらの関数に NULL を渡すとおそらくプログラムがクラッシュするでしょう) その上、いくつかの非常に便利な関数は標準関数ではありません。これが wxString の関数に加えて若干のグローバル文字列関数が存在する理由です: wxIsEmpty() は文字列が空かどうかを確かめます。(NULL ポインタに対しては true を返却します) wxStrlen() も NULL を正しく取り扱うことができ、NULL の場合は 0 を返却します。 wxStricmp() は単なるプラットフォーム非依存の大文字小文字を区別しない文字列比較関数で、プラットフォームによっては stricmp() や strcasecmp() として知られています。
また、<wx/string.h> ヘッダでは ::wxSnprintf 関数と ::wxVsnprintf 関数も定義しています。潜在的に危険な標準の sprintf() の代わりにこれらの関数を使用するべきであり、これらの関数ではバッファサイズのチェックを行なう snprintf() をできるだけ使用しています。もちろん、wxString::Printf も安全なので使用しても構いません。
他にも wxString と一緒に使用すると便利なクラスがあります: それが wxStringTokenizer です。このクラスは文字列をトークンに分解する必要があるときに便利で、標準 C ライブラリの strtok() 関数の代わりになります。
そして、文字列に関する最後のクラスが wxArrayString です: これは単なる "テンプレート" 動的配列クラスの一種で、文字列に対して使用するように特殊化されています。このクラスは (wxString の内部構造に関する知識を用いて) 文字列の格納に特化して最適化されています。そのため、wxObjectArray に wxString を格納するより性能面で優れています。
性能上の理由から、wxString は各文字列で必要とされる量ちょうどのメモリを割り当てません。代わりに、各割り当て済みブロックに少しだけメモリを追加します。割り当て済みブロックを用いることで、例えば以下のように一度に一文字ずつ連結して文字列を構築する場合などに、頻繁にメモリの再割り当てを行わなくても良くなります:
// 文字列から母音をすべて削除する wxString DeleteAllVowels(const wxString& original) { wxString vowels( "aeuioAEIOU" ); wxString result; wxString::const_iterator i; for ( i = original.begin(); i != original.end(); ++i ) { if (vowels.Find( *i ) == wxNOT_FOUND) result += *i; } return result; }
これは非常によくある状況であり、余分なメモリを割り当てない場合、著しい性能劣化を引き起こします。これは元の文字列に含まれる文字数分、メモリの (再) 割り当てが行われるためです。この場合では余分なメモリを割り当てることで処理速度が改善されましたが、通常のプログラムでは非常に多くの wxString が使用されるため、メモリ消費量も大きく増加します。
この例での最適な解決方法は wxString::Alloc() 関数を用いて、最初に例えば len バイトほど割り当てておくことです。これにより、メモリの割り当てが確実に 1 回だけ行われます。(なぜなら、変換結果の文字列の長さは最大でも元の文字列と同じだからです)
しかし、wxString::Alloc() を使用するのは手間がかかるため、wxString ではできるだけのことをしています。デフォルトのアルゴリズムでは少なくとも 16 バイト単位でメモリの割り当てが行われると仮定している (これは広く使われているほぼすべてのプラットフォームで当てはまります) ため、メモリの割り当て量が 16 の倍数に切り上げられたとしても何も無駄になりません。このように、メモリが無駄になることはありませんし、上記の例では 16 回の繰り返しのうち、15 回はメモリの割り当てが行われず、割り当て済みのプールが使用されます。
このデフォルトのやり方は非常に保守的です。より多くのメモリを割り当てることで、(相対的に) とても長い文字列を使用するプログラムでは性能が大きく向上することでしょう。割り当てられるメモリの量は string.cpp ファイルの EXTRA_ALLOC を変更することでコンパイル時に設定することができます。(値を変更する前に、なぜデフォルト値がその値になっているのかをよく理解するようにしてください!) この値を大きく (ここでは nLen の倍にしたとしましょう) したり、(性能の劣化具合を確認するために) 0 に設定したりしてプログラムに与える影響を分析しようとするかもしれません。これを行なう場合、WXSTRING_STATISTICS シンボルも定義すると便利なことにおそらく気がつくでしょう。これを定義すると wxString クラスで性能統計を収集し、プログラムの終了時に標準エラー出力へ出力させることができます。これにより、プログラムで使用する文字列の平均長、平均初期サイズ、および文字列を連結する際にメモリを割り当てず、割り当て済みのメモリを使用した回数の割合 (デフォルトの設定では約 98% のはずですが、これが 90% を下回る場合には wxString のチューニングを本当に検討するべきです) が分かります。
言うまでもないことですが、EXTRA_ALLOC を変更したときの正確な違いを計測するためにプロファイラを使用するべきです。
ANSI リテラル文字列を使用する既存のコードを 3.0 以前のバージョンと同じように動作させるために様々なことを行っています。
Unix や Linux でも wchar_t を使用する wxString が必要な場合、コマンドラインで configure --disable-utf8 スイッチを指定するか、代わりに wxUString もしくは std::wstring を使用することができます。
Unicode に対応していることを表すため、現在ではデフォルトで wxUSE_UNICODE が 1 に定義されています。wxString の内部領域に UTF-8 を使用する場合、あわせて wxUSE_UNICODE_UTF8 が定義されます。そうでない場合は wxUSE_UNICODE_WCHAR が定義されます。もっとも重要な wxUSE シンボル も参照してください。

