| Version: 2.9.4 |
この章では wxWidgets による Unicode 対応方法とプログラムへの影響について述べます。
wxWidgets 3.0 では Unicode の対応方法が大きく変わるため、以前のバージョンに関連する多くのことが、もはや正しくなくなることに注意してください。変更の詳細は Unicode に関連する変更 を参照してください。
すでに Unicode について詳しい場合、最初の 2 つの章は飛ばして、直接ライブラリの対応内容の詳細に飛んでください。
Unicode とは、 1 文字あたり 8、 16、 32 ビットを使用することで、これまでの標準的な文字コード (例えば ASCII) の欠点に対処した文字コードの標準規格のことです。これにより、 世界中の言語を一度に表現するのに十分な量のコードポイント (定義は以下を参照) が得られます。Unicode についての詳細は http://www.unicode.org/ にあります。
実用的な観点から見ると、世界中の人に向けてアプリケーションを書く時には Unicode の使用がほぼ必須と言えます。さらに、アプリケーション外で作成されたファイルを読み込んだり、ネットワーク経由で他のサービスからデータを読み込んだりするアプリケーションは Unicode を取り扱う準備をしておくべきです。
Unicode を使用するときは、いくつかの言葉を定義しておくことが重要です。
グリフ とは、文字、あるいは文字の一部を表現する特定のイメージです。 (通常はフォントの一部です) どの文字も 1 つまたは複数のグリフと関連付けられています; 例えば、大文字の 'A' であれば以下のようなグリフが関連付けられているかもしれません
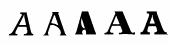
Unicode では、存在するほぼすべての文字を コードポイント と呼ばれる番号に割り当てています; 一般的に、マニュアルや Unicode のウェブサイトでは U+xxxx (xxxx は 16 進数です) という形で表現されます。
通常、ひとつの文字は厳密にひとつのコードポイントに割り当てられますが、なかには例外もあります; いわゆる 合成済み文字 (http://en.wikipedia.org/wiki/Precomposed_character 参照) や 合字 (リガチャ) のことです。これらの場合、ひとつの "文字" が複数のコードポイントにマッピングされたり、逆に複数の文字がひとつのコードポイントにマッピングされたりします。
Unicode 標準規格では取りうるすべてのコードポイントを 面 に分割しています; 面とは、連続する 65,536 (1000016) 個の Unicode コードポイントのことです。面は 0 から 16 までの番号が振られており、最初の面が BMP (基本多言語面) です。BMP にはすべての現代語の文字と、多くの特殊文字が含まれています。実際のところ、他の面は主に歴史上の文字や特殊用途の文字用か、もしくは使用されていません。
コードポイントはメモリ上ではひとつ以上の コード単位 の並びとして表現されます。コード単位とは 8、16、32 ビットといったメモリの単位のことです。より正確に言うと、コード単位とは、テキスト処理または交換のために符号化された文字を表現可能な最小のビットの組み合わせです。
UTF (Unicode Transformation Format) は Unicode コードポイントをコード単位の並びにマッピングするためのアルゴリズムです。もっとも単純なものは UTF-32 です。これは各コード単位が 32 ビット (4 バイト) から成り、各コードポイントは常にひとつのコード単位で表現される固定長エンコーディングです。 (UTF-32 であっても、リトルエンディアンとビッグエンディアンではバイト列へのマッピングが異なるため、完全に自明とはまだ言えないことに注意してください。) 一般に、UTF-32 は Unix システムにおける Unicode 文字列の内部表現に使用されています。
非常に広く使われている別の規格として、Microsoft Windows で使われている UTF-16 があります。これは最初の約 64,000 個の Unicode コードポイント (基本多言語面) を 16 ビット (2 バイト) のコード単位で符号化し、それ以降の文字は 16 ビットのコード単位の組で符号化します。これらのコード単位の組のことを サロゲート と呼びます。したがって、UTF16 は各コードポイントを符号化するために可変数のコード単位を使用します。
最後に、Unicode を外部記憶装置 (ファイルやネットワークプロトコルなど) へ格納する際に一番広く使われているのが UTF-8 です。これはバイト指向のエンコーディングであるため、 UTF-16 や UTF-32 のようにエンディアンの曖昧さがありません。UTF-8 は 8 ビット (1 バイト) のコード単位を使用します; 普通のアルファベット以外のコードポイントは可変バイトで表現されるため、内部表現としては UTF-32 よりも若干効率が落ちます。
今までに述べたコンセプトの違いを理解するため、同じコードポイントにおける UTF の表現方法の違いを見てください。
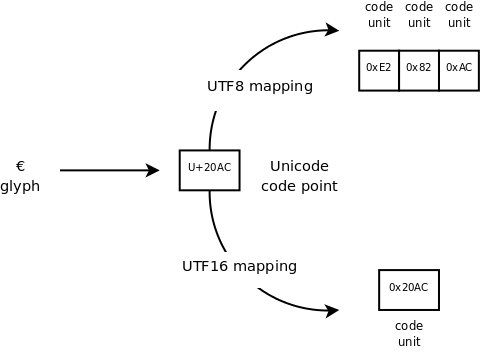
この場合では、UTF8 は UTF16 よりも多くの領域が必要となります。 (2 バイトではなく 3 バイト)
C/C++ プログラマの観点からすれば、状況はもっと複雑です。というのも、C/C++ で Unicode ( "ワイド" ) 文字列を表現するためによく使われる wchar_t 型は、すべてのプラットフォームで同じサイズとは限らないためです。Unix システムでは UTF-32 を使用してきた慣習にあわせて 4 バイトですが、Windows では UTF-16 を使用する OS との互換性のため、2 バイトとなっています。
一般的に、UTF8 を使用するときはコード単位を char に格納します。なぜなら、ほぼすべてのシステムで char 型は 8 ビットの大きさを持つためです; そして、一般的に UTF-16 を使用するときはコード単位を wchar_t 型に格納します。 wchar_t はすべてのプラットフォームで少なくとも 16 ビットだからです。これは wxString で採用されている方法でもあります。詳しくは wxString の概要 を参照してください。
上で述べた用語の正式な定義は http://unicode.org/glossary/ を参照してください。
wxWidgets 3.0 からは Unicode が常に有効になります。Unicode を使用せずにライブラリをビルドすることはまだ可能ですが、もはや非推奨であり、近い将来、サポートされなくなります。これはつまり、内部的には Unicode 文字列のみが使用され、Microsoft Windows では Unicode 版のシステム API が使用されることを意味します。そしてこれは Windows 95/98/ME で wxWidgets プログラムを実行する際に Microsoft Layer for Unicode が必要となることを意味します。
しかし、wxWidgets の以前のバージョンにおける Unicode ビルドモードとは異なり、この対応はほとんど透過的です: ワイド 文字列 (UTF16 で符号化された wchar_t* か、UTF8 で符号化された char* のことです) がサポートされていても、引き続き ナロー 文字列 (現在のロケールで符号化された char* のことです) を使用することができます。 どの wxWidgets 関数も引数を暗黙的に wxString へ変換するため、どちらの型でも受け付けます。
wxMessageBox("Hello, world!");
そして、若干、一般的ではないですが、
wxMessageBox(L"Salut \u00E0 toi!"); // U+00E0 は "グレイヴ付きのラテン小文字の a" です
これは期待した通りに動作します。
wxWidgets で使用されるナロー文字列は 常に 現在のロケールで符号化されていると仮定されます。
wxMessageBox("Salut à toi!");
これはユーザのシステムが ISO-8859-1 と互換性がない場合 (gcc の場合、別のロケールでコンパイルされたとしても) 、うまく動作しません。特に、最近の Unix システムで最もよく使われているエンコーディングは UTF-8 であり、上記の文字列は正しい UTF-8 バイト列ではないため、この場合は何も表示されないでしょう。したがって、プログラムソース内で (7 ビット文字の代わりに) 8 ビット文字列を直接しない ことが重要であり、ワイド文字列を使用するか、代わりに以下のように書いてください:
wxMessageBox(wxString::FromUTF8("Salut \xC3\xA0 toi!")); // UTF-8 では U+00E0 は 0xC3A0 と符号化される
同様に、wchar_t と char のどちらででも wxString の保持する文字列にアクセスできます。もちろん、文字列が現在のロケールのエンコーディングで表現可能である場合のみ、後者の型で正しくアクセスできます。文字列がナロー文字列か 7 ビット ASCII データで初期化されているのであれば、常にこの場合に当てはまりますが、それ以外の場合ではこの変換が常に成功することは保証されません。また、上の wxString::FromUTF8() を使ったサンプルのように、UTF-8 で符号化された文字列を取得するために常に wxString::ToUTF8() を使うことができます。この方法は、現在のロケールを使用して char* に変換する方法と比較して、変換に失敗することがありません。
wxString の挙動についての詳細は wxString の概要 を参照してください。
まとめると、wxWidgets による Unicode 対応はアプリケーションにとってほとんど 透過的 であり、wxString オブジェクトを使ってすべての文字データを格納するのであれば、特別なことをなにもする必要がありません。しかし、次の章で触れる、潜在的な問題については注意すべきです。
すべてのシステムにおいて、wxWidgets はデフォルトで wxString の実装に wchar_t を使用します。したがって、Microsoft Windows では wchar_t が 2 バイトであるため、UCS-2 (サロゲート文字をサポートしない、UTF-16 の簡略化版です) が使用されます。Mac OS X を含む Unix システムでは、デフォルトで (UTF-32 としても知られる) UCS-4 が使用されますが、設定に --enable-utf8 オプションを渡すことで内部に UTF-8 を使用するように wxWidgets をビルドすることも可能です。
wxString の提供するインタフェースはその内部フォーマットによらず、同一です。しかし、各フォーマットにはそれぞれ利点と欠点があります。特に、Unix のグラフィカルツールキット ( GTK+ など) は普通、UTF-8 文字列を使用しており、wxWidgets でも同じ符号化方式を使用することで、UI に文字列を表示するときや逆に文字列を取得するときに毎回 UTF-32 から UTF-8 に変換する必要がなくなります。この変換にかかるオーバーヘッドは小さな文字列であれば無視できるものですが、いくつかのプログラムでは重要になるかもしれません。もしあなたのアプリケーションで UTF-8 が好都合だと思うのなら、上で説明したように UTF-8 を使用するように wxWidgets をビルドし直してください。 (今のところ、Microsoft Windows ではこれに対応しておらず、Windows 自身は UTF-8 ではなく UTF-16 を使用しているため、明らかにあまり意味がないことに注意してください) ただし、これを行う前に wxString で UTF-8 を使用することによる性能への影響 (UTF-8 を使用することによる性能への影響 参照) を必ず意識するようにしてください!
一般的に言うと、リソースが限られており、変換にかかるオーバーヘッド (と、ヨーロッパ言語において UTF-32 の代わりに UTF-8 を使用することによるメモリ消費量の削減) が重要となる、といった特殊な状況下でのみ、非標準の UTF-8 ビルドを使用するべきです。(そのような状況では、よくこの場合に当てはまりますが) もしプログラムの実行される環境を制御できるのであれば、システムが常に UTF-8 ロケールを使用するようにし、--enable-utf8only オプションを使用して他のロケールのサポートを無効にすることを考慮してみてください。これはコードサイズをさらに削減させるとともに、より多くの場合で変換が不要になります。
Unicode に対応しているため、現在、 wxUSE_UNICODE は 1 として定義されています。MSW では setup.h 内で明示的に 0 にセットするか、Unix では --disable-unicode を使用することができますが、これは推奨しません。デフォルトでは wxUSE_UNICODE_WCHAR も 1 に定義されていますが、(前の章で述べた) UTF-8 ビルドでは 0 に設定されており、通常は 0 に設定されている wxUSE_UNICODE_UTF8 が代わりに 1 に設定されています。UTF-8 ビルドを行う場合、すべての文字列が UTF-8 であることを表すために wxUSE_UTF8_LOCALE_ONLY も 1 に設定することができます。
発生しうる問題は大まかに 3 種類に分類することができます:
char と wchar_t の暗黙的な相互変換をサポートする必要があるため、 wxString の実装はかなり複雑で、演算子の多くは (返却されるものと) 単純に予想される型を実際には返却しません。例えば、[] 演算子 が返却する型は char でもwchar_t でもなく、どちらの型にも変換可能なヘルパークラスである wxUniChar か wxUniCharRef です。これらの変換は裏側で行われるため、通常はこのことを気にする必要はありませんが、いくつかの場合ではうまく動作しないことがあります。その例を以下に示します。この例では wxString オブジェクト s と、ある整数 n を使用しています:
switch ( s[n] )
s[n] を次のように置き換える必要があります。 s[n].GetValue()
char か wchar_t へ変換することもできますが、 char 型への変換は現在のロケールに対して行われ、変換に失敗した場合は 0 が返却されることに注意してください。最後の注意点として、次のように書くと (wxChar)s[n]
&s[n]
char* または wchar_t* を受け取る関数に渡すことはできません。可能であれば代わりに文字列のイテレータを使用するようにするか、次のように置き換えてください。 s.c_str() + n
発生しうる別の問題は c_str() 自身の返却する値もまたバッファのポインタではなく、暗黙的にナロー文字列やワイド文字列へ変換可能なヘルパークラス wxCStrData であることに関連しています。これはほとんど目立ちませんが、いくつかの問題を引き起こすことがあります:
c_str() の戻り値を標準 printf() などの可変引数関数へ渡してはいけません。いくつかのコンパイラ (特に g++) では警告が出ますし、仮に警告が出ないとしても printf("Hello, %s", s.c_str())
wxPrintf("Hello, %s", s)
c_str() を使用していないことに注目してください。wxWidgets の関数にはそれは必要ありません)wxPrintf("Hello, %s", s.c_str())
printf("Hello, %s", (const char *)s.mb_str())
printf("Hello, %s", (const char *)s.c_str())
c_str() の戻り値は char* にはキャストできず、const char*const_cast を使用するときに役立ちます。これは新しい wxString::char_str() (や、これに対応する wchar_str()) 関数か、2 重キャストを用いることで実現できます: (char *)(const char *)s.c_str()
c_str() を使用せずに wxString を wxPrintf() へ渡せるようにした不幸な結果のひとつとして、無名 enum の要素を wxPrintf() や類似の可変長関数へ渡せなくなりました。 enum { Red, Green, Blue }; wxPrintf("Red is %d", Red);
他にも予期しないコンパイルエラーが発生することがありますが、発生頻度が上で挙げたものより少なく、解決方法も非常に単純です: コンパイラが wxUniChar と wxCStrDatajust のどちらを使用すれば良いか判断できない場合には、暗黙的な変換に頼るのではなく、明示的にそれらの関数を使用するだけです。
wxString API は内部の Unicode 文字列からナロー (char) 文字列への暗黙的な変換を行います。この変換機能は非常に便利であり、wxWidgets を使った既存コードとの後方互換性のためには絶対に欠かすことができません。しかし、これは非常に危険な操作で、文字列の内容が現在のロケールに変換できない場合は予期しない結果を簡単に引き起こします。
正確に言うと、最初にナロー文字列から文字列が作られたのであれば、変換は常に成功します。また、Unicode 文字列はすべて UTF-8 で表現することが可能なため、現在のエンコーディングが UTF-8 である場合も常に成功します。しかし、wxString::FromUTF8() 関数で初期化した文字列に対して、wxString::c_str() 関数を使って char 文字列のようにアクセスしようとするのは災いのもとです。そのプログラムは UTF-8 ロケールを使用している Unix システムでテストしている間は完璧に動作するでしょうが、UTF-8 ロケールを使用していない Windows では wxString::c_str() が空文字列を返すかもしれないため、全く動作しなくなるでしょう。
これが起きないようにする一番単純な方法は、wxString を使った char* への変換を避けることです。しかし、内部で絶対に 8 ビット文字列を操作しないというのであれば、char* ポインターを使用しても安全です。そのため、wxWidgets 3.0 にアップグレードするときは既存のコードを見直す必要があるとともに、新しいコードではこのことを意識しつつ、理想的には char* への暗黙的な変換を避けるようにするべきです。.
上で述べたように、Unix システムでは wxString クラスの内部表現に可変長の UTF-8 を使用することができます。その場合、文字列中のN 番目の要素へ定数時間でアクセスできることはもはや保証されません。なぜなら、その要素の位置を見つけるためにはその前の文字列をすべて調べる必要があるためです。大半のアルゴリズムでは文字列を逐次的に調べますし、wxString は文字列にインデックスでアクセスするためのキャッシュを持つため、通常はこのことがそれほど問題になることはありません。しかし、文字列にランダムアクセスするアルゴリズムにとっては、一般的に計算時間が O(N) から O(N^2) になる (N は文字列長です) ため、深刻な影響があります。
インデックスのキャッシュを持つとはいえ、インデックスアクセスはイテレータを使った逐次アクセスに置き換えるべきです。例えば典型的なループである、
これは以下のように書き換えるべきです。
wxString s("hello"); for ( wxString::const_iterator i = s.begin(); i != s.end(); ++i ) { wchar_t ch = *i // なんらかの処理 }
別の方法としては、ポインタ計算を使う方法があります:
wxString s("hello"); for ( const wchar_t *p = s.wc_str(); *p; p++ ) { wchar_t ch = *i // これを使って何かする }
ただし、これは文字列中に NUL 文字が含まれる場合には正しく動作しません。生ポインタと違い、イテレータを使うといくつかの実行時チェックが (少なくともデバッグビルドでは) 行われるため、一般的にはこちらの方が望ましいです。それでもポインタを使用する場合、前のセクションで述べたような変換に伴うデータ喪失の問題を避けるために char ポインタよりも wchar_t ポインタを使うようにした方が良いです。
wxWidgets が常に内部で Unicode を使うとはいえ、他のすべてのライブラリやプログラムが Unicode を使っているとは限りませんし、Unicode を使っていたとしても、別のエンコーディングを使用しているかもしれません。そのため、データを様々な表現方法へ変換できる必要がありますが、そのための wxString の関数として wxString::ToAscii()、wxString::ToUTF8() (またはそのシノニムの wxString::utf8_str())、wxString::mb_str()、wxString::c_str()、wxString::wc_str() を使用できます。
最初の関数は文字列に 7 ビット ASCII 文字のみが含まれる場合にだけ使用してください。ASCII 文字以外の文字はなんらかの置換文字に置き換えられます。wxString::mb_str() は文字列を現在のロケールで使用されているエンコーディングに変換します。そのため、Unicode の変換エラーによるデータ喪失 で述べたように、変換先のエンコーディングで表現できない文字が含まれている場合に空文字列を返却します。戻り値をナロー文字列として扱う場合には、wxString::c_str() についても同じことが言えます。最後に、wxString::ToUTF8() 関数と wxString::wc_str() 関数は絶対に失敗せず、UTF-8 で表現された char 文字列や wchar_t 文字列のポインタを常に返却します。
wxString はさらに 2 つの便利な関数を提供しています: wxString::From8BitData() と wxString::To8BitData() です。これらの関数は任意のバイナリデータをもとに wxString を作成しますが、その際にバイナリデータが現在のロケールのエンコーディングで符号化されていると仮定しません。そして、なんらかの変換や wxString::From8BitData() で行われた変換の逆変換を行うことなく、元のバイナリデータを取得することができます。このため、wxString::From8BitData() は wxString::To8BitData() によって作られた文字列に対してのみ、使用するべきです。また、これらの関数が存在しているにも関わらず、任意のバイナリデータを格納するのに wxString は理想的なクラスとは言えないことに注意してください。なぜなら、必要とされる量の最大 4 倍の領域を消費する (ワイド文字が 4 バイトのシステムで内部表現に wchar_t を使用するときがこれに該当します) ためです。代わりに wxMemoryBuffer を使用することを検討してください。
最後の注意点です: これらの関数の大半は内部文字列のポインタを直接返却するか、一時的な wxCharBuffer または wxWCharBuffer のオブジェクトを返却します。返却されたオブジェクトは暗黙的に char ポインタや wchar_t ポインタへそれぞれ変換されます。そのため、例えば wxString::ToUTF8() の戻り値を const char* を受け取る関数へ常に渡すことができます。. しかし、以下のようなコードは
const char *p = s.ToUTF8(); ... puts(p); // または const char * を受け取る他の関数の呼び出し
動作 しません。これは、wxString::ToUTF8() の返却した一時バッファが破棄され、p が存在しないアドレスを指したままになるためです。これを正しく動作させるためには、以下のようにする必要があります。
const wxScopedCharBuffer p(s.ToUTF8()); puts(p);
これは正常に動作します。
同様に、wxString::wc_str() の戻り値の型として wxWX2WCbuf を使用できます。しかし、実際には上記の関数の戻り値を別の関数へ直接渡すだけで、この謎めいた型を使用する必要がなくなります。

